패딩 (padding)
패딩이란 CPU의 효율을 높이기 위해서 효율적으로 메모리를 사용하는 기법 중에 하나이다.
(여기서의 효율이란 저장 공간 효율이 아닌 데이터 처리 속도 효율을 의미한다.)
어떤 식으로 메모리를 사용하길래 효율적이라는 걸까?
CPU의 데이터 처리 (매우 간략하게)
패딩을 설명하기 전에 CPU의 동작 방식에 대한 이해가 필요한데 너무 깊이 들어가면 이 글의 주제에서 벗어나기 때문에 간략하게 짚고 넘어가려고 한다.
요즘 대부분의 CPU 는 64bit 를 지원하는 x86_64 아키텍처를 사용하고 있다.
이것은 한 번의 CPU 연산으로 처리하는 최대 데이터의 크기가 64bit 즉, 64bit = 8byte 로 메모리에 적재된 데이터를 한 번에 8byte 까지 처리할 수 있다는 의미이다.
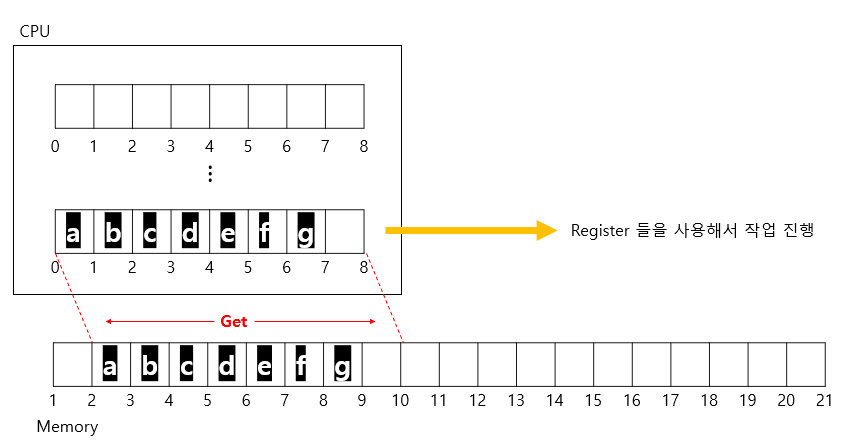
CPU는 Memory 의 주소에 접근해 데이터를 가져오고 64bit 처리를 할 수 있기 때문에 한 번에 최대 8byte 의 데이터를 처리할 수 있다. (사실 복잡한 방식을 통해서 8byte 이상의 데이터 처리도 가능하긴 하다.)
위의 그림에서는 CPU 가 단순히 Memory 에 접근해서 데이터를 가져가는 걸로 표현이 됐지만 실제로는 CPU 가 Memory 주소에 접근할 때는 아무 주소에 막 접근하지는 않는다.
데이터 관리의 효율을 높이기 위해 Memory를 block 단위로 관리하는 여러 로직들에 의해서 CPU 가 Memory 에 접근할 때에는 block 의 단위에 맞는 특정 배수의 번지수로만 접근이 가능하다.
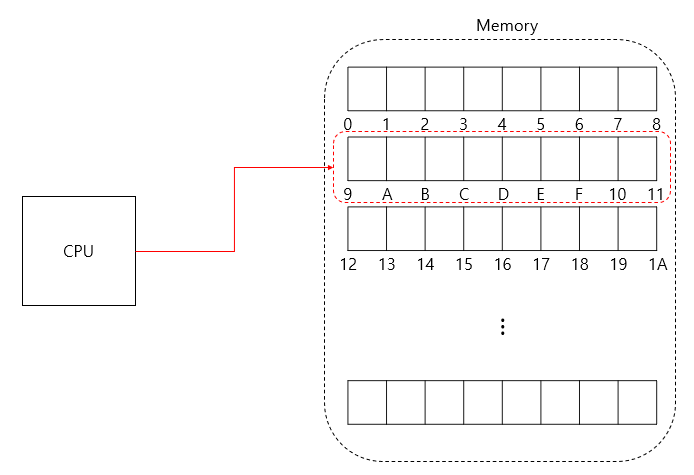
만약 데이터가 block 상관없이 memory 에 적재되어있다면 CPU 가 memory 에 접근하는 횟수가 늘어가게 되고 이는 속도 저하로 이어지게 된다.
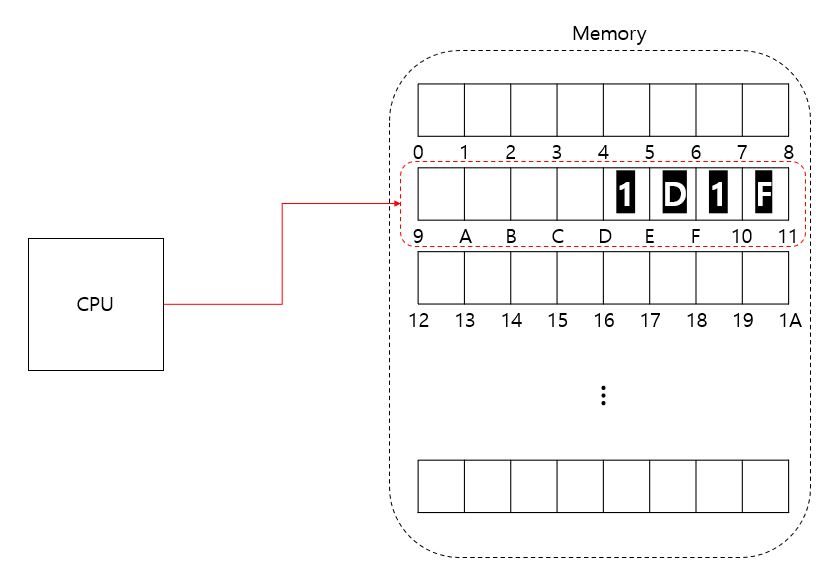
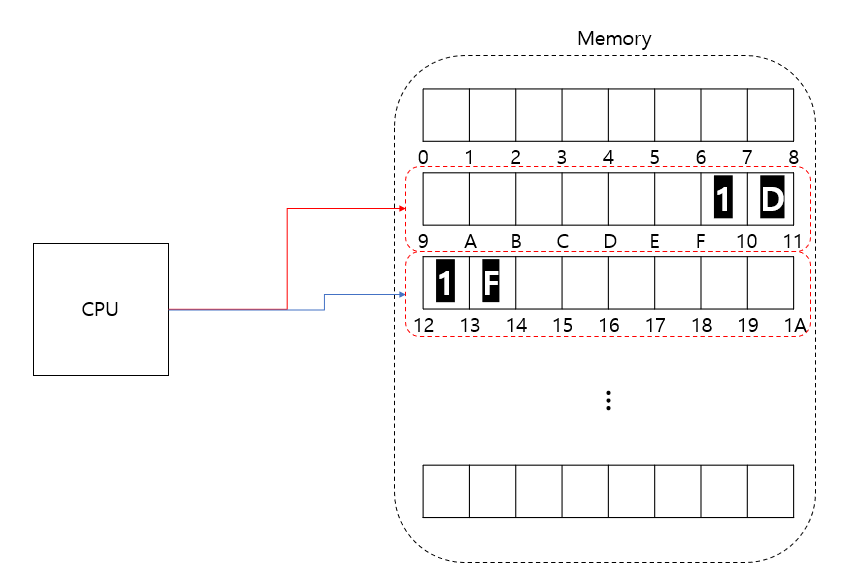
※ 실제로 CPU가 단순하게 두 번 읽지는 않는다. CPU Register 에 적재하기 위한 과정이 포함되기 때문에 속도 저하가 생각보다 많이 발생한다.
이러한 특징들로 인해 Memory 에 데이터를 적재할 때 일부러 빈 공간을 만들어서 넣는데 이것을 패딩이라고 한다.
구조체(클래스) 패딩 (padding) 규칙
효율을 위해서 memory 에 아래의 규칙을 적용해서 데이터를 적재한다.
1. 구조체(클래스) 에서 가장 큰 멤버 변수 타입의 크기를 최대 block 으로 계산한다.
(배열의 경우 배열 변수 타입을 기준으로 한다. <int 배열이면 int 타입 크기로 계산한다.>)
2. 최대 block 크기를 기준으로 순차적으로 데이터를 적재하고, block의 남은 memory 크기가 변수 타입의 크기를 넘어서면 다음 block memory 에 적재한다.
위의 규칙을 토대로 아래 예제 코드에서 구조체가 패딩 되는 것을 확인해본다.
#include <stdio.h>
#define MAX_NAME_SIZE 50
typedef struct {
char name[MAX_NAME_SIZE]; // 50 byte
char second_hand; // 1 byte
unsigned short model_year; // 2 byte
unsigned int price; // 4 byte
unsigned short seater; // 2 byte
} car_t; // 50 + 1 + 2 + 4 + 2 = 59 byte ?
int main() {
car_t car = {
"Porsche_911", // name
0, // second_hand
2020, // model_year
174000000, // price
4 // seater
};
printf("car_t : %u byte\n", sizeof(car));
return 0;
}
위의 예시 코드를 실행해보면 아래의 결과가 나온다.
car_t : 64 byte
구조체 멤버 변수의 크기 합은 59 byte 지만 실제 메모리에 적재된 구조체 크기는 64byte 로 계산된다.
위의 규칙을 적용해서 분석해보면,
cat_t 의 가장 큰 멤버 변수 타입의 크기는 unsigned int 로 4byte 이다. (char name[50] 은 char (1byte) 로 계산된다.)
따라서 아래와 같이 4byte block 의 논리적 구조를 가지게 된다.
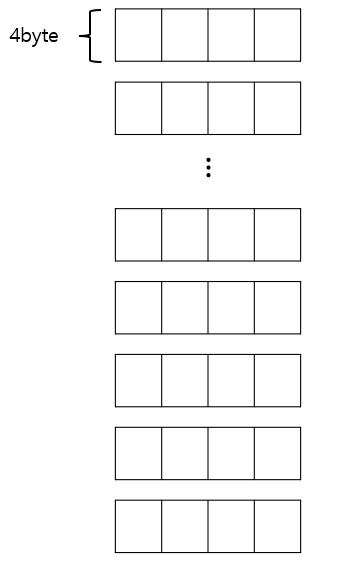
이후 4 byte block 을 기준으로 순차적으로 데이터가 적재된다.
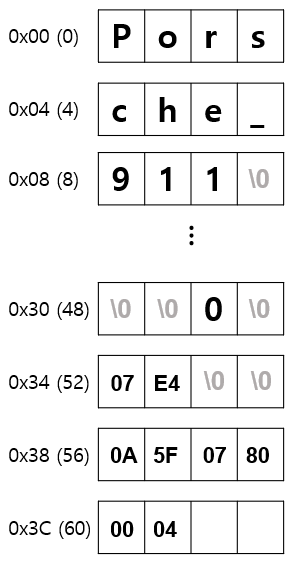
50 byte 까지 name 이 들어가고 이후 남은 2byte 에 char second_hand 가 적재된다.
그다음 데이터인 model_year 는 2byte 로 남은 1byte 에 넣을 수 없기 때문에 다음 block (0x34) 에 들어가게 된다. (2020 = 0x7E4)
다음 데이터인 price 는 4byte 로 남은 2byte 에 넣을 수 없기 때문에 다음 block (0x38) 에 들어가게 된다. (174,000,000 = 0xA5F0780)
이후 마지막 block (0x3C) 에 seater 데이터가 저장된다.
효율적인 데이터 설계
위의 규칙을 알았으니 메모리도 아끼고, CPU 성능 효율도 높일 수 있는 데이터 구조를 설계해볼 수 있다.
위에서 예시로 나온 struct car_t 의 경우 패딩 이후 64byte 의 크기를 가지게 되었는데 동일한 멤버 변수로 선언 위치만 변경해서 다시 실행해본다.
#include <stdio.h>
#define MAX_NAME_SIZE 50
typedef struct {
char name[MAX_NAME_SIZE]; // 50 byte
unsigned short model_year; // 2 byte
unsigned int price; // 4 byte
char second_hand; // 1 byte
unsigned short seater; // 2 byte
} car_t; // 50 + 1 + 2 + 4 + 2 = 59 byte ?
int main() {
car_t car = {
"Porsche_911", // name
2020, // model_year
174000000, // price
0, // second_hand
4 // seater
};
printf("car_t : %u byte\n", sizeof(car));
return 0;
}

<결과>
car_t : 60 byte
이전 코드보다 4 byte 감소한 걸 알 수 있다.
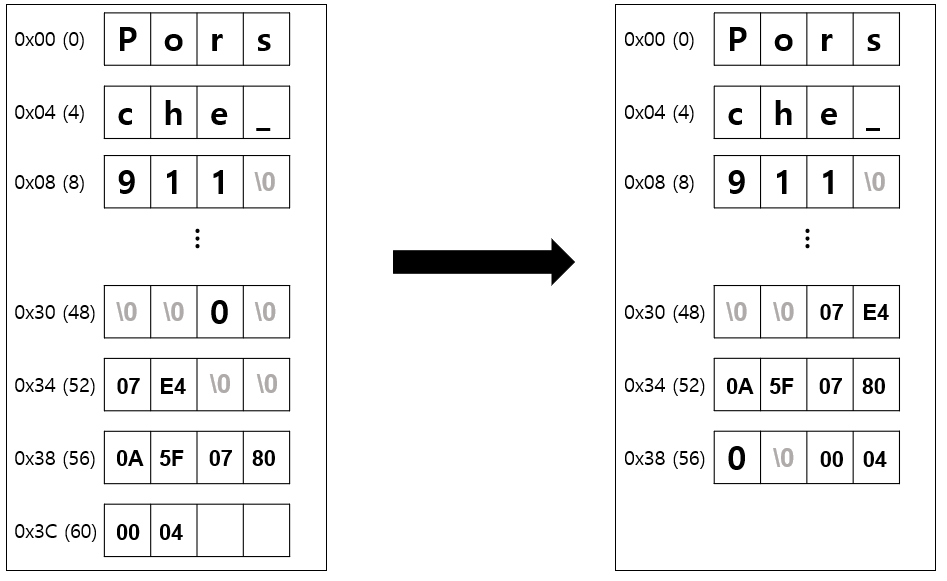
아까와 같은 방식으로 변경된 struct 에 패딩 규칙을 적용해보면 위의 그림이 나온다. (분석은 생략한다.)
결론
단순하지만 패딩 규칙을 통해서 효율적인 메모리 사용을 할 수 있고 이는 구조체 혹은 클래스가 많아지고 크기가 커지는 경우 많은 차이가 발생할 수 있게 된다.
요즘은 메모리가 남아도는 세상에서 살고 있기 때문에 크게 신경 쓰지 않아도 될 거 같지만, 아직까지 레거시가 넘쳐나고 임베디드같이 제한적인 메모리 사용을 하는 환경이 있기 때문에 분명 어딘가에서는 메모리로 고민하는 실무자가 있을 것이다.
이 글이 누군가에게는 도움이 되었으면 좋겠다.
'C언어 > 잡학사전' 카테고리의 다른 글
| [C언어] 댕글링 포인터와 와일드 포인터 (Dangling pointer & Wild pointer) (0) | 2023.03.20 |
|---|---|
| [C/C++] 구조체 패킹 (struct packing) (0) | 2022.10.11 |
| [C언어] 함수 호출 규약 (Calling Convention, cdecl, stdcall, fastcall) (0) | 2022.09.14 |
| [C언어] 포인터 오프셋 (pointer offset) (1) | 2022.09.13 |
| [C언어] 서식 지정자의 모든것 (서식문자) (0) | 2022.08.09 |